LLM2CLIP: Powerful Language Model Unlocks Richer Visual Representation
최근 Microsft에서 " LLM2CLIP: Powerful Language Model Unlocks Richer Visual Representation" 라는 제목의 논문을 발표 했습니다. 논문에 따르면 LLM2CLIP은 기존 CLIP보다 더 강력한 텍스트 이해를 얻을 수 있으며 많은 이미지 캡션 데이셋에서 최첨단 검색 성능을 달성했다고 합니다. 이번 블로그에서는 LLM2CLIP의 내용을 확인하고 CLIP과 비교해보도록 하겠습니다.
먼저 LLM2CLIP과 CLIP은 LLM2Vec의 두가지 기술에 영향을 받기 때문에 CLIP과 LLM2Vec을 확인하고 LLM2CLIP을 확인해보겠습니다.
CLIP
CLIP는 OpenAI가 개발한 멀티모달 모델 중 하나로 Transformer 아키텍처를 기반으로 하는 이미지 및 텍스트 인코더로 구성되며 제로샷 이미지 분류를 위해 설계 되었으며 접근 방식은 아래와 같습니다.

첫번째 단계로 Contrastive pre-training 에서 CLIP은 contrastive loss로 학습되어 이미지 및 텍스트 인코더의 이미지 및 텍스트 feature를 정렬합니다. contrastive loss은 쌍을 이룬 이미지 및 텍스트 feature를 유사하게 만들지만 쌍을 이루지 않는 이미지 및 텍스트 feature는 다르게 만듭니다. 따라서 CLIP은 이미지 및 텍스트 인코더간에 동일한 feature 공간을 공유하며 이미지와 텍스트를 구별하는 기능을 얻을 수 있습니다.
이후 이미지와 텍스트 후보를 준비하고 이미지 feature와 가장 유사한 텍스트를 선택하여 동작합니다.
LLM2Vec
LLM2Vec은 Decoder 전용 대형 언어 모델(LLM)을 강력한 Text Encoder로 변환하는데 사용되는 기술입니다.
LLM2Vec은 아래 3가지 단계로 구성됩니다.
- 양방향 어텐션 활성화
- 마스크된 다음 토큰 예측
- 비지도 대조 학습

1. 양방향 어텐션 활성화
- 디코더 전용 LLM의 causal attention mask 전체를 1로 대체하여 각 토큰이 다른 모든 토큰에 접근할 수 있도록 변환합니다.
- BERT와 같은 인코더 모델에서 사용하는 양방향 Attention mask 는 단어간 관계를 이해할 수 있어 임베딩 표현에 효과가 있습니다.
2. 마스크된 다음 토큰 예측
- Bidirectional attention을 모델에 반영하기 위해서 입력 시퀀스에서 일부 토큰을 마스킹한 후, 모델이 과거와 미래 컨텍스트를 기반으로 마스크된 토큰을 예측하도록 학습합니다.(MNTP)
- MNTP는 전체 시퀀스에서 각 단어의 표현을 학습하여 LLM이 의미와 맥락을 고려하는 더 나은 임베딩 표현을 얻을 수 있도록 합니다.
3. 비지도 대조 학습(SimCSE)
- 이전 두 단계는 각 단어(토큰)에 대한 더 나은 임베딩 표현에만 초점을 맞추었지만 문장을 구별하기에는 충분하지 않습니다.
- 따라서, 시퀀스 표현 능력 향상을 위해 SimCSE를 적용하여 동일 시퀀스의 두 표현 간 유사도를 최대화하고 다른 시퀀스 표현과의 유사도는 최소화 합니다.
- 이는 유사한 문장의 임베딩을 더 가깝게 만들고 유사하지 않은 문장의 임베딩을 더 멀리 만들 수 있는것이며 LLM이 전체 문장 의미를 고려하여 문장을 구별할 수 있게 됩니다.
LLM2CLIP
대형 언어 모델(LLM)이 광범위한 자연어 처리 기능을 보여주는 반면, CLIP 텍스트 인코더는 길고 복잡한 텍스트 정보를 처리할 수 없기 때문에 제한된 기능으로 간주되어 왔습니다. 이는 CLIP 텍스트 인코더의 한계가 CLIP 이미지 인코더의 추가 개선 가능성을 제한하기도 합니다. 저자들은 LLM을 활용하여 CLIP이 더 강력하고 세밀하며 풍부한 시각적 표현을 학습할 수 있도록 LLM2CLIP을 개발했습니다.
LLM2CLIP은 아래 두 단계로 나눌 수 있습니다.
- LLM2Vec 접근법을 적용하여 LLM을 텍스트 인코더로 변환
- LLM 기능 공간을 정렬하기 위해 CLIP Vision Image Encoder 미세조정
먼저 LLM2CLIP은 LLM2Vec 접근 방식을 사용하여 LLM을 인코더로 변환합니다. 하지만 왜 LLM을 CLIP Text Encoder로 직접 대체할 수 없을까요 아래 그림을 통해 저자가 일부 모델에서 caption retrieval 진행한 실험을 토대로 사실을 확인할 수 있습니다.

그림처럼 Llama는 Clip Text Encoder 보다 캡션 검색 작업에 성능이 낮은것을 확인할 수 있습니다. 따라서 저자는 LLM2Vec를 먼저 적용하여 LLM을 임베딩 작업과 정렬시킵니다. 모델이름에 'CC'가 적힌 모델은 LLM2Vec이 적용된것으로 CLIP보다 더 나은 결과를 얻을 수 있었습니다.
두번째 단계에서는 CLIP 시각적 공간과 LLM 특징 공간을 정렬해야 합니다. 이전 단계에서 강력한 텍스트 인코더를 얻을 수 있었지만, 특징 공간은 아직 정렬 되지 않았습니다. 필요한 계산 자원을 줄이기 위해 LLM 가중치를 고정하고 어댑터와 프로젝터 레이어를 도입하여 비전 인코더를 정렬합니다.
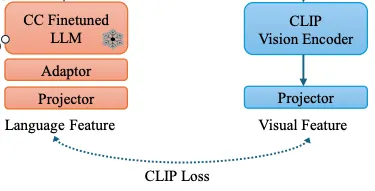
LLM2CLIP은 미세조정 시 CLIP Loss 만 사용하고, 학습 효율성 측면에서 vanlia CLIP은 학습에 500개 이상의 V100 GPU가 필요하지만, LLM2CLIP은 8개의 H100 GPU만 필요하고, 9시간의 훈련시간으로 충분하다고 합니다.
효율적인 훈련 비용에도 LLM2CLIP은 이미지 캡셔닝 작업에서 SOTA 결과를 달성할 수 있게 되었습니다.
next steps
vanlia CLIP, LLM2CLIP 이미지 유사도 검색 성능 비교를 통해 처리 속도 및 정확도 평가